7 características no orientadas a objetos de C++ que puedes comenzar a utilizar inmediatamente en tus proyectos en C
(Read this article in english here.)
Modern C++
En el mundo de los sistemas embebidos existen mitos sobre C++ y todos ellos han logrado que muchos programadores no quieran adoptarlo, aún sin investigar si podría ser una buena inversión. Pocos o ninguno de esos mitos es verdad; quien sea que los diga se quedó pensando en el C++ de los 90’s.
Otra razón para que C++ no sea ampliamente adoptado es que muchos programadores de sistemas embebidos no ven ninguna ganancia en cambiar al paradigma orientado a objetos y prefieren quedarse programando de manera procedimental. No hay nada de malo en esto, pero la Programación Orientada a Objetos (POO) en muchas ocasiones nos permite representar nuestras ideas en código de manera más clara.
(Por cierto, es posible escribir programas POO en C; yo lo hago todo el tiempo, pero la sintaxis no es tan elegante como la de C++. Recuerda: “La POO está en la mente del programador, no en el lenguaje”).
Un mito muy extendido es que los programas en C++ son grandes y pesados, y que por lo tanto este lenguaje no debe ser usado para sistemas embebidos. En palabras del propio creador de este lenguaje (Bjarne Stroustrup):
“C++ está hecho para sistemas embebidos”.
Bjarne Stroustrup
Por otro lado y siguiendo la misma idea, C++ cumple con dos promesas hechas desde el nacimiento del lenguaje:
- “Leave no room for a lower-level language below C++”. El único lenguaje más eficiente que C++ debe ser el ensamblador, y sólo en algunos casos muy específicos.
- “What you don’t use you don’t pay for”. C++ está lleno de características, pero que las tenga no significa que se le cargarán a tu programa aunque no las uses. Además, muchas de estas características tienen costo cero comparadas contra sus equivalentes en C, como las que te voy a presentar.
C++ puede ser utilizado en una variedad de paradigmas de programación, y los consejos que hoy te quiero compartir no tienen nada que ver con la programación orientada a objetos; esto es, puedes continuar programando de manera procedimental en C++ y obtener mucho provecho de las características que te voy a platicar.
Antes de comenzar, recuerda: no tienes que usar todas las características de C++ para usarlo en tu proyecto, pero en particular evita el uso de:
- Excepciones.
- RTTI.
- La STL (Standard template library).
- Y como siempre, mantén al mínimo la utilización de memoria dinámica.
Antes de comenzar hablemos sobre las versiones de C++ que podemos utilizar.
The older, the mature: ¿qué versión de C++ usar?
“C++11 se siente como un nuevo lenguaje” (“C++11 feels like a new language”)
Bjarne Stroustrup
Antes de la versión 11, C++ evolucionaba muy lento; pero a partir de ella su desarrollo ha sido mucho más rápido, tanto que cada 3 años sale una versión con cambios significativos (por eso existen C++11, C++14, C++17 y C++20). A C++11 y posteriores le llamamos “Modern C++” y así te lo vas a encontrar en mucha literatura.
Sin embargo, y muy importante en los sistemas embebidos, debemos mantenernos alejados de las versiones más recientes. Como lo dice el título de esta sección “entre más viejo, más maduro”:
- Un compilador es un programa de software, y como cualquier software, tiene errores. Vamos a esperarnos a que los arreglen.
- Los fabricantes de compiladores (ya sean OpenSource (como GCC, el estándar para sistemas embebidos) o propietarios (VC, entre otros) se toman un tiempo antes de implementar la versión más reciente del estándar, por lo cual una o varias características aprobadas para el lenguaje podrían no estar incluídas, a pesar de que el fabricante le llame C++20, por ejemplo.
Las características que te voy a mostrar a continuación todas están implementadas a partir de C++11, pero donde sea necesario o conveniente, indicaré su posible alternativa en una versión más reciente, como C++17 (siendo ésta versión mi límite en esta introducción).
Para compilar con C++11 en GNU-GCC (el estándar):
g++ -Wall -std=c++11 -oexec.out main.cpp
Para compilar con C++17 en GNU-GCC:
g++ -Wall -std=c++17 -oexec.out main.cpp
1 Compila tus programas de C con el compilador de C++
C++ es un lenguaje fuertemente tipeado y mucho más estricto que C. Si intentas compilar tu proyecto actual que está en C con C++, seguramente te aparecerán un montón de errores que jamás pasaron por tu cabeza. Cosas que parecen triviales en C, en C++ son consideradas como errores.
g++ -Wall -std=c++17 -oexec.out main.cpp
No te preocupes por el tamaño del ejecutable, será el mismo que obtendrías con C (cuando logres que compile).
Algunas plataformas muy populares en el mundo de los sistemas embebidos utilizan a C++ como lenguaje nativo de desarrollo, por ejemplo, Arduino y Mbed. (Por increíble que parezca, pocos usuarios de Arduino saben que están desarrollando en C++; muchos creen que existe un lenguaje llamado “Arduino”.)
Vale la pena mencionar que es posible mezclar código en C con código en C++; por ejemplo, los device drivers de los periféricos internos y externos a nuestros microcontroladores están la mayoría escritos en C, pero tú puedes escribir tu aplicación en C++ e interactuar con toda la infraestructura existente en C. De igual manera, algunos sistemas operativos en tiempo real muy utilizados, como FreeRTOS, Zephyr OS y Linux, están escritos en C, pero nada impide que escribas tu aplicación en C++.
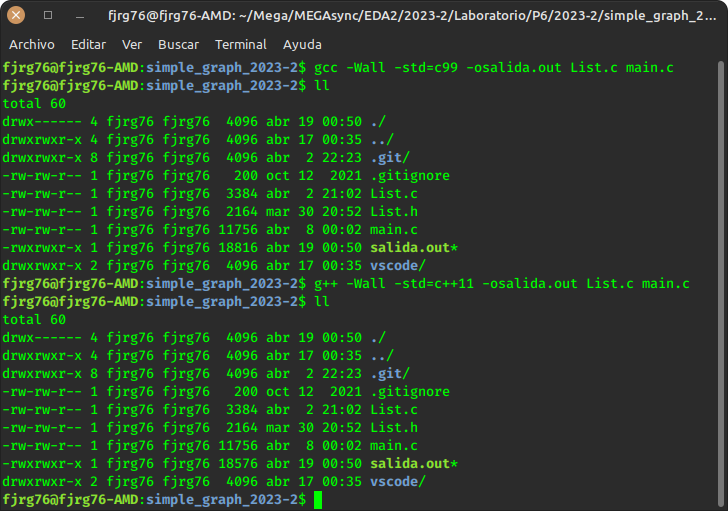
La siguiente imagen muestra la compilación de un programa de grafos escrito en C, tanto en C como con C++. Observa el tamaño de los ejecutables generados; y aunque esto no es una regla, ni debes tomarla como tal, el ejecutable generado con C++ es más pequeño. Lo que sí es una regla es que nunca será más grande:
Debo aclarar que, dado que programo en ambos lenguajes, mis programas en C, que son compilados con el compilador de C (por cuestiones de mis estudiantes), están pensados para no hacer enojar al compilador de C++:
int* array = malloc( 10 * sizeof( int ) ); // (1) Ok en C, error en C++ int* array = (int*) malloc( 10 * sizeof( int ) ); // (2) Ok en C y C++
En mis programas en C utilizo la forma (2).
Da el primer paso hacia C++ utilizando este compilador en tus nuevos proyectos.
COSTO: 0
2 Organiza tu código con los namespace’s (espacios de nombres)
Imagina que estás desarrollando sobre la plataforma Arduino y se te ocurre el siguiente nombre para una de tus funciones: digitalWrite() (suele suceder). Cuando la uses en tu programa el compilador se quejará porque habrá encontrado otra función con el mismo nombre. Y ya sea que estés enamorado del nombre de tu función, o que simplemente este nombre refleja tus intenciones, ¿qué harías? Cambiarle el nombre no es opción.
A esta situación, muy común, le llamamos name clashes (colisión de nombres) y es el escenario perfecto para comenzar a utilizar namespace’s (espacios de nombres). Un namespace agrega información adicional a todos los elementos que sean declarados o definidos dentro de él (funciones, variables, clases, etc); es como agregarle un apellido al nombre de cada entidad:
namespace fjrg76
{
void digitalWrite( uint8_t pin, bool new_state )
{
// set the new_state to the pin
}
} // no semicolon is required after the closing brace
int main()
{
digitalWrite( 1, HIGH ); // Arduino's API function. In C++ it's an unqualified name
fjrg76::digitalWrite( 2, LOW ); // your awesome function. In C++ it's a fully qualified name
}
Como podrás observar, tu función ha sido declarada (y definida) dentro del namespace fjrg76 (por supuesto puedes ponerle el nombre que quieras) y ya no existirá en aislamiento, siempre que quieras usarla deberás agregarle el nombre que usaste para el namespace seguido de “::” (doble dos puntos) (:: es el operador de resolución de ámbito de C++).
Además de evitar la duplicidad de nombres, también sirven para organizar tu código, ya sea a nivel de archivo por funcionalidad, o a nivel de sistema de archivos en proyectos más grandes.
El siguiente ejemplo muestra cómo usar a los namespace’s para organizar nuestro código por funcionalidad:
namespace fjrg76
{
namespace Inputs
{
bool digitalRead( uint8_t pin )
{
return 0;
}
// more functions related to inputs ...
}
namespace Outputs
{
void digitalWrite( uint8_t pin, bool new_state )
{
// set the new_state to the pin
}
// more functions related to outputs ...
}
}
int main()
{
if( fjrg76::Inputs::digitalRead( 3 ) == LOW )
{
fjrg76::Outputs::digitalWrite( 2, HIGH );
}
}
Quizás hayas observado que los nombres de nuestras entidades cada vez se hacen más largos:
fjrg76::Outputs::digitalWrite( 2, HIGH );
C++ tiene la solución para ello: los alias. Un alias (o sinónimo) es un segundo nombre, quizás más corto, pero igual de descriptivo, para cualquier entidad válida en el lenguaje. En C++ usamos using para declarar alias, y en el tema que estamos abordando, podemos acortar el nombre de diferentes maneras y hasta una profundidad que no nos devuelva al problema original. Vamos a eliminar el nombre del programador (fjrg76):
// namespace declaration same as before
using namespace fjrg76; // (1)
using fjrg76::Outputs::digitalWrite; // (2)
int main()
{
if( Inputs::digitalRead( 3 ) == LOW ) // Using (1)
{
digitalWrite( 2, HIGH ); // Using (2)
// be aware of name clashes!
}
}
(1) Nos permite eliminar el primer nivel en la jerarquía (el nombre del programador, fjrg76), pero debemos seguir agregando el nombre de los namespace’s internos (Inputs y Outputs).
(2) Nos permite llamar a la entidad por su nombre original (digitalWrite()), y dado que esta entidad es una función y no un espacio de nombres, entonces no debemos agregarle la palabra reservada namespace. ¡Ten cuidado! Si estás seguro que no tendrás colisiones de nombres, entonces usa esta forma; en caso contrario regresarás al problema original. ¿Estamos usando nuestra digitalWrite() o la de Arduino?
C++17 nos permite simplificar la notación cuando tenemos namespace’s anidados. En lugar de:
namespace A
{
namespace B
{
namespace C
{
int a;
}
}
}
podemos hacer:
namespace A::B::C
{
int a;
}
Nuestro ejemplo de namespace’s por funcionalidad nos quedaría así:
namespace fjrg76::Inputs
{
bool digitalRead( uint8_t pin )
{
return 0;
}
// more functions related to inputs ...
}
namespace fjrg76::Outputs
{
void digitalWrite( uint8_t pin, bool new_state )
{
// set the new_state to the pin
}
// more functions related to outputs ...
}
COSTO: 0
3 Utiliza las enumeraciones cualificadas para tus máquinas de estados
La mayoría de nuestros proyectos embebidos están basados en o usan máquinas de estado finitas, normalmente las codificamos como case’s dentro de un switch, y en los discriminadores de los case’s usamos números enteros o enumeradores.
Corremos varios riesgos al utilizar los enumeradores nativos de C:
- Colisión de nombres.
- Mezclar los enumeradores con enteros.
- Olvidar uno o varios case’s en el switch.
3.1 Colisión de nombres y enumeradores cualificados
Los enum class son un nuevo tipo de dato en C++11 (esto es, parecen int’s pero no son int’s) y además, como lo dice el título de esta sección, están cualificados; es decir, los enumeradores no existen en aislamiento: siempre deberás indicar a quién pertenecen (una idea similar a la de los namespace’s). La cualificación completa evita la colisión de nombres y vuelve más claras nuestras intenciones.
En C podríamos escribir algo así:
enum{ RED, YELLOW, GREEN }; // Traffic lights, fruits, jackets?
Mientras que en C++11 nuestra intención es clara como el agua:
enum class Traffic_ligth{ RED, YELLOW, GREEN }; // Semaphore is a new user data type
Traffic_ligth sem = Traffic_ligth::RED; // sem is of type Traffic_ligth
if( sem == Traffic_ligth::GREEN){ ... } // Complete qualification
enum class FruitColor{ RED, YELLOW, GREEN }; // Ok
Fruit fruit = FruitColor::YELLOW; // Ok
No te preocupes por los nombres largos, tu editor de código fuente te completará el nombre de la enumeración y te mostrará los diferentes enumeradores.
3.2 Los enum class no son enteros, son un tipo de datos
Que los enum class sean un tipo de datos significa que no puedes tratar a sus enumeradores como un int; además, no puedes usar los enumeradores sin indicar la clase a la que pertenecen:
sem = 2; // Error: you can't assign an int to a variable of type Traffic_ligth
if(sem == GREEN){...} // Error: GREEN identifier isn't defined
Otra ventaja es que puedes ahorrar memoria indicando el número de bits que tus enumeradores van a utilizar. Por default el tamaño del entero base es de una word (32 bits en la mayoría de los casos), pero tú tienes la posibilidad de indicar una cantidad menor, por ejemplo, 8 bits y sin signo (por si no lo requieres):
enum class Semaphore: uint8_t{ RED, YELLOW, GREEN };
3.3 Debes usar todos los enumeradores en un switch
Lo mejor de todo es que ¡C++11 te avisará si te faltan uno o más enumeradores en tu lista de case‘s! (debes agregar la bandera -Wall en la instrucción de compilación, ¿siempre la usas, cierto?):
switch( sem )
{
case Semaphore::RED:
cout << "Stop\n";
break;
case Semaphore::YELLOW:
cout << "Slow down\n";
break;
}
warning: enumeration value 'GREEN' not handled in switch [-Wswitch]
16 | switch( sem )
| ^
(Código compilado con la bandera -Wall.)
COSTO: 0
4 Literales definidas por el usuario (Define tus propios literales)
Muchas plataformas, Arduino, FreeRTOS, mbed, etc, incluyen funciones para realizar retardos (delay( ms ), vTaskDelay( ms ), wait( sec ), respectivamente). En las primeras dos el argumento está dado en milisegundos, mientras que en la última está en segundos.
Para indicar un retardo de 5 segundos en Arduino debes escribir:
delay( 5000 ); // or delay( 5 * 1000 );
Mientras que para indicar un retardo de 5 segundos en FreeRTOS debes escribir:
vTaskDelay( 5000 / portTICK_PERIOD_MS );
Aparte de la sintaxis horrible siempre debes recordar que el argumento está en milisegundos.
¿No sería mejor que pudiéramos indicar el tiempo en cualquier divisor y que C++ se encargue del resto? Algo así como:
delay( 5_sec ); // or delay( 1_min ); // or delay( 600_ms );
Afortunadamente C++11 incluye las literales definidas por el usuario (UDL: user-defined literals). Este tema puede llegar a resultar algo confuso, sin embargo, para el escenario planteado es bastante simple: sólo queremos que C++ se encargue de la conversión y que al mismo tiempo nos permita indicar las unidades de medida, como en el ejemplo anterior.
Las UDL las declaramos así:
constexpr return_type operator"" _xxx( yyy );
donde:
- constexpr le indica al compilador que realice la conversión en tiempo de compilación debido a que, al final del día, las UDL son constantes.
- return_type es cualquier tipo de retorno válido. Recuerda que estamos realizando una conversión.
- operator«» es el operador que le indica a C++ que estamos declarando una UDL.
- _xxx es el nombre del prefijo que deseamos (_ms, _sec, _min). Tanto el guión bajo (_), como el espacio entre las comillas y el (_) son obligatorios.
- yyy es uno de dos tipos para el argumento: para enteros es unsigned long long int; mientras que para números reales es long double. (También podemos realizar conversiones con cadenas, pero ese tema queda fuera de esta introducción.)
Veamos cómo nos quedarían un par de UDL’s para el ejemplo con la función delay() de Arduino:
// convert milliseconds to milliseconds (just for API completeness):
constexpr uint32_t operator"" _ms( unsigned long long time_in_ms )
{
return static_cast<uint32_t>(time_in_ms); // (1)
// assuming that the base time is 1ms
}
// convert seconds to milliseconds:
constexpr uint32_t operator"" _sec( unsigned long long time_in_sec )
{
return static_cast<uint32_t>(time_in_sec * 1000);
// assuming that the base time is 1ms
}
void loop()
{
delay( 3_sec );
// ...
}
(1) static_cast<>() es otra característica de C++11: conversión explícita entre tipos, mejor conocido como casting; también podrías usar: return (uint32_t) time_in_ms, pero es mejor que empieces a familiarizarte con todos esos mecanismos de C++ que no son orientados a objetos.
¿Qué hay detrás de las UDL’s? Es muy simple, es syntactic sugar para realizar conversiones. Mientras que nosotros lo humanos escribiríamos:
delay( 5_sec );
C++ internamente considera la llamada anterior como:
delay( _sec( 5 ) );
Finalmente, otro uso de las UDL’s es la conversión entre unidades de medida diferentes, por ejemplo pasar de millas a kilómetros, teniendo como base el metro. Desde afuera podemos escribir las unidades que más nos convengan en ese punto de nuestro código (millas o kilómetros), pero internamente estaremos trabajando con metros:
constexpr float operator"" _miles( long double dist_in_miles )
{
return static_cast<float>( dist_in_miles * 1609.3 );
}
constexpr float operator"" _kms( long double dist_in_kms )
{
return static_cast<float>( dist_in_kms * 1000.0 );
}
int main()
{
auto my_dist1 = 5.0_miles;
auto my_dist2 = 2.0_kms;
cout << "dist1: " << my_dist1 << " m" << endl;
cout << "dist2: " << my_dist2 << " m" << endl;
}
$ ./literals.out
dist1: 8046.5 m
dist2: 2000 m
$
COSTO: 0
5 Referencias y nullptr
5.1 Referencias
Para muchos principiantes del lenguaje el tema de los apuntadores les pone los pelos de punta, y no es para menos. Además, la notación con apuntadores puede llegar a ponerse un poco confusa en muchas situaciones del día a día.
Por otro lado, un apuntador está inmediatamente por encima del hardware; esto es, existe un mapeo 1 a 1 entre los apuntadores y la memoria, y cualquier error con los apuntadores hará que el programa termine abrúptamente.
¿Y qué hace un apuntador? Pues es una variable que hace referencia a otra localidad de la memoria, pero a un nivel muy bajo de abstracción. Un problema muy común en C que todos hemos experimentado es intentar desreferenciar un apuntador que apunta ya sea a basura o a nada, con resultados catastróficos (todos hemos estado ahí):
int* p = NULL; *p = 5;
C++11 introdujo las referencias, las cuales hacen casi lo mismo que los apuntadores, pero un nivel de abstracción por encima y a costo cero. Para empezar una referencia siempre debe apuntar, o mejor dicho, referenciar, a un objeto; esto es, no existen las referencias nulas.
Para declarar referencias debemos usar al símbolo & como prefijo de la variable referencia:
int a = 7; int& r_a = a; // Ok: r_a immediately references an int variable int& r_b; // Error: reference not initialized r_a = 11; // Ok: now a has the value 11
a es una variable entera normal, mientras que r_a es una referencia a una variable entera. Nota tres cosas:
- Dado que hará referencia a una variable int, entonces se declara como int&.
- Debe ser inicializada inmediatamente.
- Hace referencia a la variable a sin utilizar el símbolo (&) de los apuntadores.
Si intentas declarar una referencia sin inicializarla, el compilador arrojará un error.
Veamos un ejemplo:
int a = 5;
int& r = a; // r references the variable a
cout << "a: " << a << ", r: " << r << endl;
int b = 7;
r = b; // same as a = b
cout << "a: " << a << ", r: " << r << endl;
Salida:
$ ./references.out a: 5, r: 5 a: 7, r: 7 $
Por otro lado, e igual de importante, una referencia no puede cambiar de objeto al que apunta (fuera de su inicialización como argumento de una función):
int a = 5;
int& r = a;
int b = 7;
r = b; // Ok: a takes (through the reference r) the value of b
int& r = b; // Error: redeclaration of r
r = &b; // Error: cannot assign an int address to a int reference
Por cierto, y a diferencia de los apuntadores, las referencias no tienen dirección; esto es, no existe forma de obtener la dirección de una referencia ni existe ningún mecanismo para guardarla.
Un uso muy interesante es con las funciones y tipos compuestos ya que simplifica un poco la notación. Cuando queremos mandar un objeto grande (una estructura) como argumento de una función, por eficiencia debemos mandar su dirección (paso de argumentos por referencia), y dentro de la función, tenemos que utilizar al operador flecha (->) para accesar a los campos del objeto. Las referencias simplifican la notación, como lo muestra el siguiente ejemplo, el cual muestra, lado a lado, apuntadores y referencias:
struct S
{
int d;
};
void f_p( S* p, int val ) // argument passing by reference, using pointers
{
p->d = val; // (1)
}
void f_r( S& r, int val ) // argument passing by reference, using references
{
r.d = val; // (2)
}
int main()
{
S x;
f_p( &x, 3 ); // (3)
cout << "Pointer: x.d: " << x.d << endl;
S y;
f_r( y, 5 ); // (4)
cout << " Ref: x.d: " << x.d << endl;
}
(1) Usamos al operador flecha dado que la función recibió la dirección de una variable estructura.
(2) La función f_r() recibe una referencia y el acceso a los campos es a través del operador punto.
(3) Enviamos la dirección del objeto x a través del operador (&).
(4) Solamente escribimos el nombre de la variable que queremos enviar, sin símbolos extras; el compilador ya sabe que se trata de una referencia.
Quizás no parezca mucho en este momento cambiar una flecha por un punto, pero si en algún momento decides utilizar la biblioteca estándar de C++ (STL), entonces estarás agradecido de que existan las referencias.
Y si tal vez estás pensando que no vale la pena utilizar referencias en lugar de los antiguos apuntadores, recuerda que no puedes enviar referencias que no apunten a nada, lo cual en C (pasar apuntadores nulos) es un dolor de cabeza. Esta característica agrega un nivel de seguridad a nuestros programas
f_p( NULL, 3 ); // Ok in C (source of troubles) f_r( ?, 5 ); // Error at various levels. It won’t compile
Finalmente quiero mencionarte que muchos libros contemporáneos de C++ evitan u omiten el tema de los apuntadores y en su lugar describen y usan a las referencias (y en general evitan tratar temas de C). Esto es un claro indicativo que debemos preferir las referencias a los apuntadores siempre que sea posible; esto es, si nuestro código está un nivel por encima del hardware, entonces usemos referencias.
COSTO: 0
5.2 nullptr
Ahora que, si por gusto o necesidad deseas o tienes que utilizar apuntadores, entonces prefiere nullptr en lugar de la macro NULL.
nullptr es una palabra reservada en C++11 que representa direcciones nulas, mientras que NULL es simplemente el valor cero (quizás del tipo entero):
int* p = 0; // Ok int* q = nullptr; // Ok int v = NULL; // Ok (warning) int w = nullptr; // Error: nullptr isn’t an integer
TAREA: Este ejemplo lo tomé de AQUÍ. Sin ver la respuesta trata de determinar cuál función, 1 o 2, es la que se llama:
void func(int n); // (1) void func(char *s); // (2) func( NULL ); // guess which function gets called?
(Sí, C++ permite que dos o más funciones tengan el mismo nombre, siempre y cuando sus argumentos, o número de éstos, sea diferente. Esta característica se llama sobrecarga de funciones.)
COSTO: 0
Para finalizar solamente quiero mencionar que C++11 incluye apuntadores inteligentes (smart pointers) pero no los menciono en esta introducción porque están ligados a la memoria dinámica, y en los sistemas embebidos intentamos no utilizar a este tipo de memoria. Sin embargo, si en tu proyecto vas a utilizar memoria en el heap, quizás quieras revisarlos; son más seguros que los apuntadores en bruto y su costo es casi cero (para los apuntadores unique_ptr() su costo es cero).
6 Constantes y alternativas al #define para constantes simbólicas
Muchas de nuestras aplicaciones usan tablas o conversiones. Si la tabla sigue alguna fórmula, entonces podríamos calcular el valor de cada elemento de la tabla cuando el programa inicia. ¡Terrible idea!
Si calcularlos en tiempo de ejecución no es opción, entonces podríamos crear una hoja de cálculo y que ésta determine el valor de cada elemento de la tabla. No se oye tan mal. El problema es que si la fórmula depende de un valor semilla que además sea variable, entonces la solución con la hoja de cálculo no funcionará (piensa en una tabla de passwords calculados y únicos a cada microcontrolador).
En los sistemas embebidos nos gusta que todo lo que se pueda calcular en tiempo de compilación se calcule en tiempo de compilación. Previo a C++11, y sólo bajo ciertas condiciones, esto era posible; sin embargo, si C++11 determina que un cálculo puede realizarse en tiempo de compilación, entonces lo hará, siempre y cuando le indiquemos que se trata de una expresión constante.
C++11 introdujo las expresiones constantes (constexpr). Una expresión constante es una expresión que puede ser evaluada en tiempo de compilación. Recordemos que una expresión es cualquier construcción en el lenguaje que calcule o devuelva un resultado.
En el siguiente ejemplo podemos ver que es muy probable que la expresión b=a*8 sea ejecutada cuando el programa ya se está ejecutando, a pesar de que está conformada por constantes. Por otro lado, la expresión d=c*8 será ejecutada cuando el programa se está compilando; de ahí el nombre de expresión constante. En la práctica es como haber escrito directamente d=40:
int main()
{
int a = 5; // a is neither const nor constexpr
const int b = a * 8; // it might be evaluated when compiling the program
constexpr int c = 5; // c is constant
constexpr int d = c * 8; // it's evaluated when compiling the program
}
Por otro lado, es común declarar constantes con #define:
#define MAX 50
Pero, ¿cuál es el tipo de MAX: int, char, unsigned, long, …? Además, el depurador GDB no maneja muy bien las constantes simbólicas. #define simplemente substituye el símbolo MAX con el valor 50 donde sea que se lo encuentre en nuestro programa. ¿Cómo podríamos agregarle el tipo a la constante MAX? Podemos usar constexpr para declarar constantes simbólicas:
constexpr uint32_t MAX = 50; // (1)
int main()
{
uint8_t array[ MAX ]={0};
}
(1) Ahora hemos declarado que MAX es del tipo unsigned int (aka: uint32_t).
COSTO: 0
const vs constexpr
¿Cuál es la diferencia entre const y constexpr? const declara a una variable como de sólo lectura, pero su evaluación será en tiempo de ejecución (cuando el programa ya se está ejecutando); mientras que constexpr también declara a una variable como de sólo lectura, pero la evalúa en tiempo de compilación (cuando el programa se está compilando).
7 El nuevo if: restringiendo el alcance de las variables (C++17)
Mientras mantengamos el alcance de las variables lo más reducido posible, mejor. Una variable existe desde su creación hasta la llave de cierre del bloque donde se declaró. En C antiguo debíamos declarar todas las variables al principio de las funciones; después, C99 nos permitió declarar variables en cualquier parte de la función, y fue por una razón: reducir al máximo el riesgo de usar o cambiar el valor de variables por error.
Así mismo, C99 ya nos permitía declarar la variable de control dentro de la declaración de los ciclos for:
for( uint32_t i = 0; i < MAX; ++i )
{
printf( "%d\n", i ); // Ok: i only exists inside this block ({})
}
i = 5; // Error: i doesn’t exist outside the previous block
En C antiguo teníamos que hacer lo siguiente:
{
uint32_t i; // i exists from here to the next closing brace
for( i = 0; i < MAX; ++i )
{
printf( "%d\n", i );
}
i = 5; // Ok: i still exists
} // i stops existing from now on
i = 10; // Error: i doesn't exist outside the previous block
En situaciones triviales es indiferente que las variables existan durante toda la vida de una función; sin embargo, cuando escribimos código seguro debemos limitar el alcance de las variables; es decir, desde dónde y por cuánto tiempo deberán existir.
No obstante, y a pesar de que C99 nos deja declarar variables justo antes de utilizarlas, en ocasiones, tanto en C como en C++, debemos abrir un bloque ({}) que limite el alcance de una variable crítica que sabemos que no debe existir fuera de un cierto contexto (justo como en el ejemplo anterior con la variable i). C++17 ya nos permite declarar la variable dentro de la declaración de la instrucción if, a partir de lo que se ha llamado if initializer:
if( init; cond ){}
En lugar de escribir:
int critical_var = f();
if( critical_var < 10 )
{
// we should use the critical variable just inside this block
}
critical_var = 0; // Ups, we shouldn't, but we can: troubles in the horizon
podemos hacer lo siguiente:
if( int critical_var = f(); critical_var < 10 )
{
// critical_var only exist inside this block ({})
}
critical_var = 0; // Error: critical_var doesn’t exist outside the previous block
Otra ventaja es que no debemos inventar nombres que sólo logran obscurecer el código. Antes de C++17:
int critical_var = f();
if( critical_var < 10 ){}
unsigned critical_var2 = g(); // Ugly
if( critical_var2 < 10 ){}
Con C++17:
if( int critical_var = f(); critical_var < 10 ){}
if( unsigned critical_var = g(); critical_var < 10 ){} // Better!
COSTO: 0
8 Extras
auto
C++11 puede determinar el tipo de una variable a partir del contexto:
float f(){}
auto var = f(); // var is of type float
Inicialización sin reducción (Non-narrowing initialization)
En C/C++ antiguos lo siguiente es posible:
int a = 9999; char b = a; // It compiles anyway
Con C++11 podemos mejorar hasta cierto punto esta situación utilizando la inicialización sin reducción:
int a = 9999;
char b = a; // Not even a warning
int c = -1000;
unsigned d{c}; // Wrong, but at least we get a warning
int e{3.14}; // Narrowing error
Range for
Podemos recorrer colecciones (arreglos) con una nueva forma compacta del for: el range-for:
int arr[5] = {2,3,5,7,11};
for( auto& elem : arr )
{
cout << elem << ", ";
}
cout << endl;
Si nuestra intención es recorrer la colección y hacer algo con cada elemento de la misma, entonces podemos dejar de usar el for tradicional y comenzar a usar el range-for.
Nota: A pesar de que el arreglo es de números enteros, por eficiencia (y memoria muscular) es costumbre hacer que el campo elem sea del tipo referencia.
using
¿Usas apuntadores a funciones para tus callbacks? Lo más seguro es que sí:
typedef int( *pf )( int, int );
La palabra reservada using nos permite declarar un apuntador a función (entre otras cosas) de manera más limpia:
using pf = int (*)(int, int);
Y en tus funciones que reciben la callback, la sigues utilizando igual; el único cambio fue en la declaración.
Más aún, C++11 nos permite mover el tipo de retorno hacia el final:
using pf = auto (*)(int, int) -> int;
Veamos un ejemplo típico de los sistemas embebidos:
typedef void (*pf)(int); // The C way
using pf2 = auto (*)(int) -> void; // Using using
void g( int d ) // The callback
{
cout << d << endl;
}
void DoSomething1( pf user_code ) // Use it as usual
{
user_code( 5 );
}
void DoSomething2( pf2 user_code ) // Use it as usual
{
user_code( 5 );
}
int main()
{
DoSomething1( g );
DoSomething2( g );
}
8 Antes de terminar
C++11 y posteriores incluyen una gran cantidad de características independientes de la programación orientada a objetos que podemos comenzar a utilizar en nuestros sistemas embebidos.
En esta introducción no pude incluir todas, pero mi idea es que comiences a ver a C++ como una alternativa real a C.
Y como lo pudiste notar, muchas de estas características tienen costo cero rompiendo el mito que C++ crea ejecutables más grandes.
Finalmente, aunque utilizar un cierto lenguaje no hace que sea más o menos seguro (eso depende de lo bueno que sea el programador), C++ nos facilita que nuestros programas sean más seguros, compactos, fáciles de leer y fáciles de mantener.
¿Ya has usado alguna de estas características? ¿Cuáles? ¿Quieres comentar algo? ¡Adelante, házmelo saber en los comentarios!

Mi perfil completo lo puede encontrar en: https://www.linkedin.com/in/fjrg76-dot-com/
- Arduino and ESP32 whims - diciembre 17, 2025
- Writing Scalable Firmware: Implementing the Command Pattern in C++ - diciembre 4, 2025
- Patrón de diseño de software Command para sistemas embebidos para los no iniciados - noviembre 30, 2025
1 COMENTARIO