The format of this article is different from the regular ones. The reason is that I want to post as soon as possible the quircks and whims I've found now…
Categoría: Blog
Writing Scalable Firmware: Implementing the Command Pattern in C++
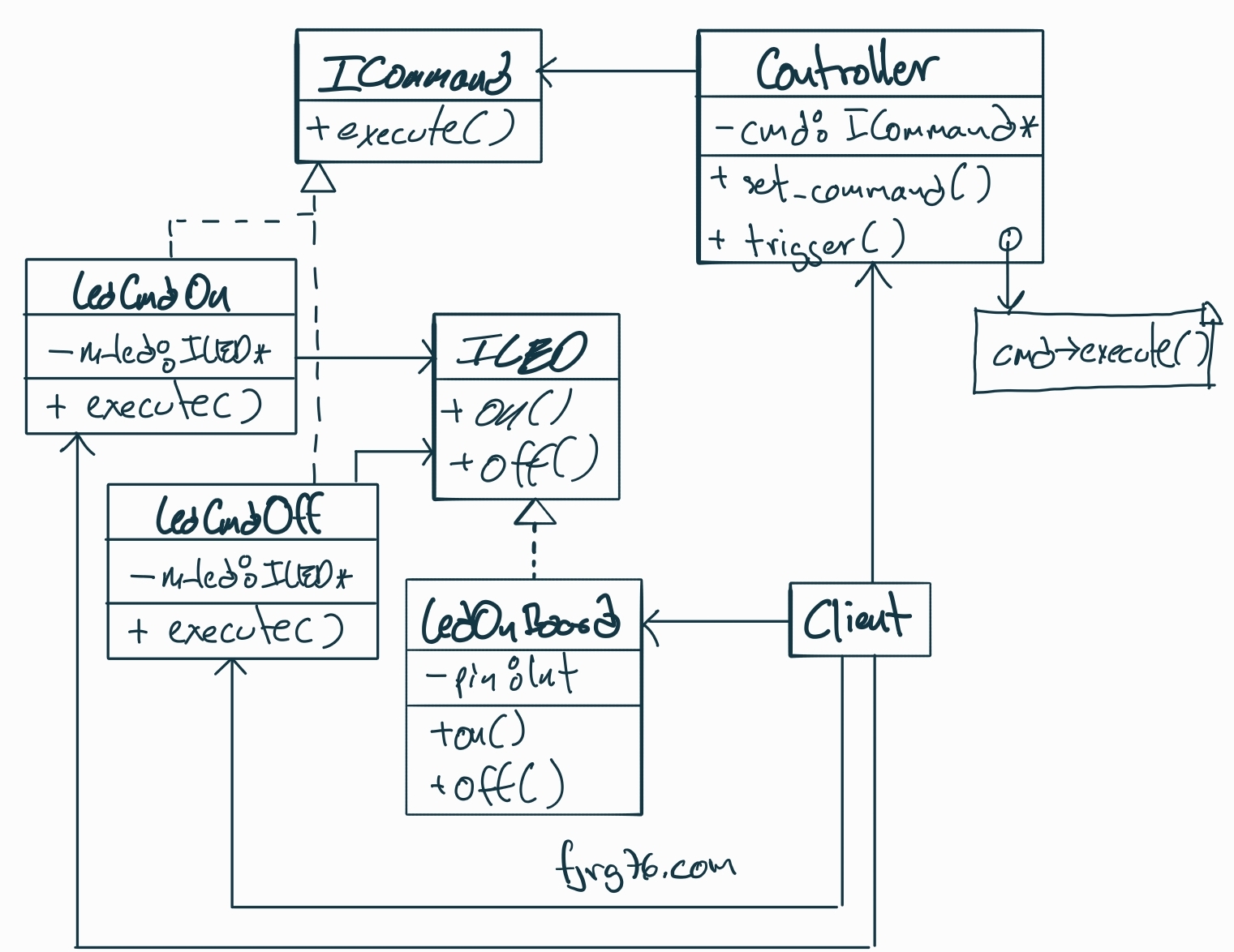
In this article, we will review the basic concepts of this pattern—adapted to the context of our embedded systems—and then we will build a practical, straightforward example: an LED controlled…
Patrón de diseño de software Command para sistemas embebidos para los no iniciados
En este artículo revisaremos los conceptos básicos de este patrón —adaptados al contexto de nuestros sistemas embebidos— y luego construiremos un ejemplo práctico y sencillo: un LED controlado mediante comandos.…
Breathe Life into Your Displays with the Arduino Print Class

Wouldn't it be amazing if there was a nearly automatic way to get your display printing correctly, professionally, and without having to start from scratch every time? Keep reading –…
Esta clase poco conocida de Arduino le dará vida a tus displays de texto y te olvidarás de tener que escribir funciones de conversión
Introducción ¿Construiste un display y luego te volviste loco escribiendo funciones de conversión para imprimir cadenas de texto y números? ¿Construiste un segundo display y te viste haciendo exactamente lo…
Printable: The class you didn’t know existed in Arduino and that you won’t be able to stop using
The class Printable provides an easy, fast, and safe way to add printing functionality to your classes in different scenarios, like the ones I set out above, without duplicating your code.
Printable: La clase que no sabías que existía en Arduino y que no podrás dejar de usar
La clase Printable provee una forma fácil, rápida y segura de agregar la funcionalidad de imprimir a tus clases en diferentes escenarios sin duplicar tu código y utilizando la infraestructura…
Is your code asking too many questions? Learn how the «Tell, Don’t Ask» principle can make your objects do the talking
Although programming is one of my two greatest passions, I had no academic training in it, beyond introductory courses while studying Electronics Engineering. Along the way, while I was self-taught…
¡Hazlo, no preguntes! O sobre cómo dejar de abusar de los getters
A pesar de que la programación es una de mis dos más grandes pasiones no tuve formación académica en ésta, más allá de cursos introductorios mientras estudiaba Ingeniería en Electrónica.…
7 non-object oriented C++ features that you could start using in your C projects right away!
Para español presiona aquí. Modern C++ In the embedded systems world there are myths about C++ and all of them have led many programmers not want to adopt it, even…