7 non-object oriented C++ features that you could start using in your C projects right away!
Para español presiona aquí.
Modern C++
In the embedded systems world there are myths about C++ and all of them have led many programmers not want to adopt it, even without investigating whether it could be a good investment. Few if any of these myths are true; whoever says so, he or she is kept thinking about C++ from the 90s.
Another reason C++ is not widely adopted is that many embedded programmers see no benefit in switching to the object oriented paradigm and they prefer to stay programming in the procedural one. There is nothing wrong with this, but Object Oriented Programming (OOP) often allows us to represent our ideas in code more clearly.
(It is possible to write OOP programs in C; I do it all the time, but the syntax is not as elegant as C++. Remember: “OOP is in the mind of the programmer, not in the language”).
A widespread myth is that programs in C++ tend to be big and heavy, and therefore this language should not be used for embedded systems. In the words its creator (Bjarne Stroustrup):
“C++ is made for embedded systems”.
Bjarne Stroustrup
On the other hand, and pursuing the same ideales, C++ fulfills two promises made since its conception:
- “Leave no room for a lower-level language below C++”. The only language more efficient than C++ must be assembler, and only in some very specific cases.
- “What you don’t use you don’t pay for”. C++ is full of features, but just because it has them doesn’t mean they’ll be loaded into your program even if you don’t use them. Also, many of these features are zero cost compared to their C equivalents, like the ones I’m going to introduce you to.
C++ can be used in a variety of programming paradigms, and the tips I want to share with you today have nothing to do with object-oriented programming; that is, you can continue programming procedurally in C++ and get a lot of benefits from the features that I am going to talk about.
Before we start, remember: you don’t have to use all the features of C++ to use it in your project, but in particular avoid using:
- Exceptions.
- RTTI.
- The STL (Standard template library).
- And as always, keep dynamic memory usage to a minimum.
Let’s start!
The older, the mature: which version of C++ to use?
“C++11 feels like a new language”
Bjarne Stroustrup
Before we dive into the details, let’s talk about the versions of C++ that we can use.
Previously to the version 11, C++ evolved very slowly; but from then on its evolution has been much faster, every 3 years a version comes out with significant changes (that’s why there are C++11, C++14, C++17 and C++20). C++11 has been called “ModernC++” and so you will find such reference in literature a lot.
However, and very important for embedded systems, we must stay away from the most recent versions. As the title of this section has stablished “the older, the more mature”:
- A compiler is a software program, and like any software, it has bugs. Let’s wait for the language programmers to fix them.
- Compiler vendors (whether OpenSource or proprietary) take time before implementing the most recent version of the standard, so one or more features approved for the language might not be included, even though the manufacturer calls it C++20, for example.
The features that I am going to show you below are all implemented as of C++11, but where necessary or convenient, I will indicate their possible alternative in a more recent version, such as C++17 (being this version my limit in this introduction).
To compile with C++11 on GNU-GCC (the standard) you can do:
g++ -Wall -std=c++11 -oexec.out main.cpp
To compile with C++17 on GNU-GCC you can do:
g++ -Wall -std=c++17 -oexec.out main.cpp
Compile your C programs with the C++ compiler
C++ is a strongly typed language and much stricter than C. If you try to compile your project that is currently in C with the C++ compiler, you will surely get a lot of errors that never crossed your mind. Things that seem trivial in C are considered bugs in C++.
g++ -Wall -std=c++17 -oexec.out main.cpp
Don’t worry about the size of the executable, it will be the same as what you would get with C.
Some very popular platforms in the embedded world use C++ as their native development language, for example, Arduino and Mbed. (As incredible as it may sound, few Arduino users know they are developing in C++; many believe that there is a language called «Arduino».)
It is worth mentioning that it is possible to mix C code with C++ code; for example, the device drivers. Most of the internal and external microcontroller peripherals are written in C, but you can write your application in C++ and interact with all existing infrastructure in C. Similarly, some widely used real-time operating systems, such as FreeRTOS, Zephyr and Linux are written in C, but nothing prevents you from coding your application in C++.
The following image shows the compilation, both in C and with C++, for a data structure called graph written in C. Look at the size of the generated executables; and although this is not a rule, nor should you take it as such, the executable generated with C++ is smaller. What effectively is a rule is that it will never be bigger.
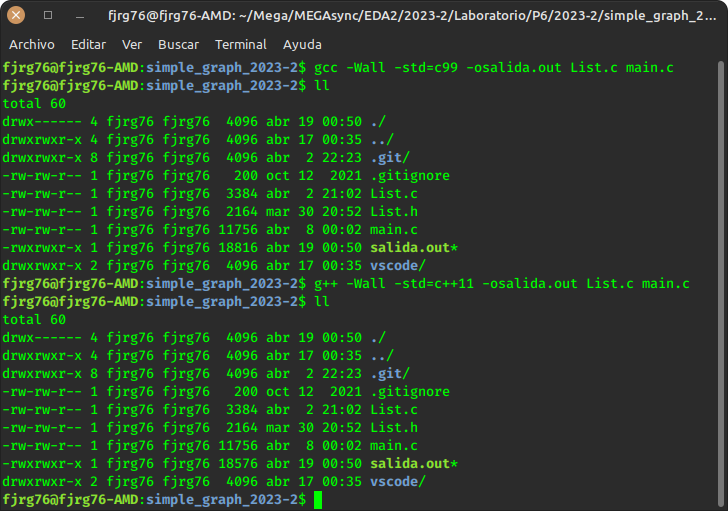
I should clarify that, since I program in both languages, my C programs, which are compiled with the C compiler (as per my CS teacher job), are meant not to anger the C++ compiler:
int* array = malloc( 10 * sizeof( int ) ); // (1) Ok en C, error en C++ int* array = (int*) malloc( 10 * sizeof( int ) ); // (2) Ok en C y C++
I use the form number (2) in my C programs .
Take the first step towards C++ by using this compiler in your new projects.
COST: 0
Organize your code (and your ideas) with the namespace’s
Imagine that you are developing on the Arduino platform and you come up with the following name for one of your functions: digitalWrite() (happens from time to time). The compiler will complain when you use it in your program because it will have found another function with the same name. And whether you’re in love with the name of your function, or it simply reflects your intentions, what would you do? Renaming it is not an option.
We call this very common situation name clashes and is the perfect scenario to start using namespace’s (namespaces). And namespace adds additional information to all the elements that are declared or defined within it (functions, variables, classes, etc); It’s like adding a last name to the name of each entity:
namespace fjrg76
{
void digitalWrite( uint8_t pin, bool new_state )
{
// set the new_state to the pin
}
} // no semicolon is required after the closing brace
int main()
{
digitalWrite( 1, HIGH ); // Arduino's API function. In C++ it's an unqualified name
fjrg76::digitalWrite( 2, LOW ); // your awesome function. In C++ it's a fully qualified name
}
As you can see, your function has been declared (and defined) within the namespace fjrg76 (of course you can name it whatever you want) and it will no longer exist in isolation, whenever you want to use it you must add the name you used for the namespace followed by «::” (double colon) (:: is the C++ scope resolution operator).
In addition to avoiding duplication of names, they also serve to organize your code, either at the file level for functionality, or at the file system level in larger projects.
The following example shows how to use the namespace’s to organize our code by functionality:
namespace fjrg76
{
namespace Inputs
{
bool digitalRead( uint8_t pin )
{
return 0;
}
// more functions related to inputs ...
}
namespace Outputs
{
void digitalWrite( uint8_t pin, bool new_state )
{
// set the new_state to the pin
}
// more functions related to outputs ...
}
}
int main()
{
if( fjrg76::Inputs::digitalRead( 3 ) == LOW )
{
fjrg76::Outputs::digitalWrite( 2, HIGH );
}
}
Cool, isn’t it?
You may have noticed that our entity names are getting longer and longer:
fjrg76::Outputs::digitalWrite( 2, HIGH );
C++ has the solution for this: the alias. An alias (or synonym) is a second name, perhaps shorter, but just as descriptive, for any valid entity in the language. In C++ we use the reserved word using to declare aliases (among other things), and in the topic at hand, we can shorten the name in different ways deep enough that doesn’t return us to the original problem. Let’s remove the programmer’s name (fjrg76):
// namespace declaration same as before
using namespace fjrg76; // (1)
using fjrg76::Outputs::digitalWrite; // (2)
int main()
{
if( Inputs::digitalRead( 3 ) == LOW ) // Using (1)
{
digitalWrite( 2, HIGH ); // Using (2)
// be aware of name clashes!
}
}
(1) It allows us to remove the first level in the hierarchy (the name of the programmer, fjrg76), but we must continue adding the name of the namespace internal ’s (Inputs and Outputs).
(2) It allows us to call the entity by its original name (digitalWrite()), and since this entity is a function and not a namespace, then we should not add the keyword to it namespace. Be careful! If you’re sure you won’t have name collisions, then use this form; otherwise you will return to the original problem: Are we using our digitalWrite() function or the Arduino’s?
C++17 allows us to simplify the notation nesting namespace’s.
Rather than:
namespace A
{
namespace B
{
namespace C
{
int a;
}
}
}
we can write:
namespace A::B::C
{
int a;
}
Our example of namespace’s for functionality would look like this:
namespace fjrg76::Inputs
{
bool digitalRead( uint8_t pin )
{
return 0;
}
// more functions related to inputs ...
}
namespace fjrg76::Outputs
{
void digitalWrite( uint8_t pin, bool new_state )
{
// set the new_state to the pin
}
// more functions related to outputs ...
}
COST: 0
Use qualified enums for your state machines
Most of our embedded projects are based on or use finite state machines, FSM, and we normally code them as case’s inside a switch, and for the case’s discriminators we use integers or enumerators.
We run several risks when using native C enumerators:
- Name collision.
- Mix enumerators with integers.
- Forget one or morecase’s in theswitch.
Let’s address each one of this issues.
Collision of names and qualified enumerators
The enum class (qualified enumerators) are a new data type in C++11 (that is, they look like int’s, but they are not int’s) and also, as the title of this section says, they are qualified; that is, enumerators do not exist in isolation: you must always indicate who they belong to (a similar idea to that of namespace’s). Full qualification avoids name collisions and makes our intentions clearer.
In C we are allowed to write something like this:
enum{ RED, YELLOW, GREEN }; // Traffic lights, fruits, jackets?
Whereas in C++11 our intent is crystal clear:
enum class Traffic_ligth{ RED, YELLOW, GREEN }; // Semaphore is a new user data type
Traffic_ligth sem = Traffic_ligth::RED; // sem is of type Traffic_ligth
if( sem == Traffic_ligth::GREEN){ ... } // Complete qualification
enum class FruitColor{ RED, YELLOW, GREEN }; // Ok
Fruit fruit = FruitColor::YELLOW; // Ok
Don’t worry about long names, your source code editor will fill in the enum name and show you the different enumerators.
enum class’es are not integers, they are a data type
That the enum class be a data type means you can’t treat their enumerators as int’s; Also, you can’t use enumerators without indicating the class to which they belong.
sem = 2; // Error: you can't assign an int to a variable of type Traffic_ligth
if(sem == GREEN){...} // Error: GREEN identifier isn't defined
Another advantage is that you can save memory by specifying the number of bits that your enumerators are going to use. By default the size of the underlying integer is one word (32 bits in most cases), but you have the possibility to indicate a smaller amount, for example, 8 bits and unsigned (in case you don’t require the sign):
enum class Semaphore: uint8_t{ RED, YELLOW, GREEN };
You must use all enumerators on a switch
Best of all, C++11 will let you know if you are missing one or more enumerators in your list of case‘s! (you must add the flag -Wall in the compiler instruction, anyway you always use it, don’t you?):
switch( sem )
{
case Semaphore::RED:
cout << "Stop";
break;
case Semaphore::YELLOW:
cout << "Slow down";
break;
}
warning: enumeration value 'GREEN' not handled in switch [-Wswitch]
16 | switch( sem )
| ^
(Code compiled using the -Wall flag.)
COST: 0
User defined literals
Many platforms (Arduino, FreeRTOS, Mbed, etc) include functions to perform time delays (delay( ms ), vTaskDelay( ms ), wait( sec ), respectively). For the first two functions the argument is given in milliseconds, while in the last one it is given in seconds.
To indicate a time delay of 5 seconds in Arduino you must write:
delay( 5000 ); // or delay( 5 * 1000 );
Whereas to indicate a 5 second time delay in the FreeRTOS real time operating system you must write:
vTaskDelay( 5000 / portTICK_PERIOD_MS );
Awful syntax aside you should always remember that the argument is in system ticks! (Hopefully most of the time one tick is equivalent to one millisecond.)
Wouldn’t it be better if we could indicate the time in any divisor and have C++ take care of the rest? Something like:
delay( 5_sec ); // or delay( 1_min ); // or delay( 600_ms );
Fortunately C++11 includes what is called user defined literals (UDL for short). This topic can be a bit confusing, however, for the proposed scenario it is quite simple: we only want C++ to take care of the conversion and that at the same time allows us to indicate the units of measurement, as in the previous example.
The general syntax for declaring UDLs is like this:
constexpr return_type operator"" _xxx( yyy );
where:
- constexpr tells the compiler to do the conversion at compile time because, at the end of the day, UDLs are constants.
- return_type is any valid return type. Remember that we are performing a conversion.
- operator«» is the operator that tells C++ that we are declaring a UDL.
- _xxx is the name of the prefix we want (_ms, _sec, _min, _Km, _miles, _litters, etc). Both, the underscore (_) and the space between the quotes and the underscore, are required.
- yyy is one of two types for the argument: for integers it is unsigned long long int; while for real numbers it is long double. (We can also perform conversions with strings, but that is beyond the scope of this introduction.)
Let’s code some UDL’s for the Arduino’s function delay():
// convert milliseconds to milliseconds (syntatic sugar just for API completeness):
constexpr uint32_t operator"" _ms( unsigned long long time_in_ms )
{
return static_cast<uint32_t>(time_in_ms); // (1)
// assuming that the base time is 1ms
}
// convert seconds to milliseconds:
constexpr uint32_t operator"" _sec( unsigned long long time_in_sec )
{
return static_cast<uint32_t>(time_in_sec * 1000);
// assuming that the base time is 1ms
}
// convert minutes to milliseconds:
constexpr uint32_t operator"" _min( unsigned long long time_in_min )
{
return static_cast<uint32_t>(time_in_min * 60 * 1000 );
// assuming that the base time is 1ms
}
void loop()
{
delay( 1234_ms ); // Nice!
// ...
delay( 3_sec ); // Cool!
// ...
delay( 1_min ); // Cooler!
}
(1) static_cast<>() is another C++11’s feature: explicit conversion between types, better known as casting; you could still use: return (uint32_t) time_in_ms, but you’d better start getting familiar with all those nicer C++ mechanisms that aren’t object oriented.
What is behind the UDL’s? It’s very simple, it’s syntactic sugar for performing conversions. Whereas we humans would write:
delay( 5_sec );
This function call is internally considered by C++ as:
delay( _sec( 5 ) );
Finally, another scenary where the UDL’s shine is the conversion between different units of measurement, for example going from miles to kilometers, given the Meter as the underlying base unit, for example. From the outside we can write the units that are most convenient for us at that point in our code (miles or kilometers), but internally we will be working with meters.
constexpr float operator"" _miles( long double dist_in_miles )
{
return static_cast<float>( dist_in_miles * 1609.3 );
}
constexpr float operator"" _kms( long double dist_in_kms )
{
return static_cast<float>( dist_in_kms * 1000.0 );
}
int main()
{
auto my_dist1 = 5.0_miles;
auto my_dist2 = 2.0_kms;
cout << "dist1: " << my_dist1 << " m" << endl;
cout << "dist2: " << my_dist2 << " m" << endl;
}
$ ./literals.out
dist1: 8046.5 m
dist2: 2000 m
$
COST: 0
References and nullptr
References
For many language beginners, the subject of pointers freezes them, and it is not for less. Also, notation with pointers can get a bit confusing in many day-to-day situations, even for the seasoned programmer.
On the other hand, a pointer is immediately above the hardware; that is, there is a 1-to-1 mapping between the pointers and memory, and any error made with pointers will cause the program to terminate abruptly.
And what does a pointer do? Well, it is a variable that does reference to another memory location, but at a very low level of abstraction. A very common problem in C that we have all experienced is trying to dereference a pointer that points to either garbage or nothing, with catastrophic results (we’ve all been there, don’t say you haven’t).
int* p = NULL; *p = 5;
C++11 introduced the references, which behaves almost the same as pointers, but they’re one level of abstraction above memory and incurs in zero cost. First thing we can say about references is that a reference always should reference to an object; that is, there are not Nil references.
To declare references we must use the ampersand & in between the type and the reference variable:
int a = 7;
int& r_a = a; // Ok: r_a immediately references an int variable
int& r_b; // Error: reference not initialized
r_a = 11; // Ok: now a has the value 11
a is a normal integer variable, while r_a is a reference to an integer variable. From the above snippet you can observe three things:
- Since it will reference a variable int, then it is declared as int&.
- It must be initialized immediately.
- It refers to the variable a without using the symbol (&) from the pointers.
If you try to declare a reference without initializing it, the compiler will throw an error.
Let’s see another example:
int a = 5;
int& r = a; // r references the variable a
cout << "a: " << a << ", r: " << r << endl;
int b = 7;
r = b; // same as a = b
cout << "a: " << a << ", r: " << r << endl;
Output:
$ ./references.out a: 5, r: 5 a: 7, r: 7 $
On the other hand, and just as important, a reference cannot change the object it points to (outside of its initialization as a function argument):
int a = 5;
int& r = a;
int b = 7;
r = b; // Ok: a takes (through the reference r) the value of b
int& r = b; // Error: redeclaration of r
r = &b; // Error: cannot assign an int address to a int reference
By the way, unlike pointers, references have no address; that is, there is no way to obtain the address of a reference nor is there any mechanism to store it.
A very interesting use of references is with functions and compound types since it simplifies the notation a bit. When we want to send a large object (a structure) as a function argument, for efficiency we must send its address (passing arguments by reference), and inside the function, we have to use the arrow operator (->) to access the object’s fields. The references simplify the notation, as shown in the following example, which shows pointers and references side by side:
struct S
{
int d;
};
void f_p( S* p, int val ) // argument passing by reference, using pointers
{
p->d = val; // (1)
}
void f_r( S& r, int val ) // argument passing by reference, using references
{
r.d = val; // (2)
}
int main()
{
S x;
f_p( &x, 3 ); // (3)
cout << "Pointer: x.d: " << x.d << endl;
S y;
f_r( y, 5 ); // (4)
cout << " Ref: x.d: " << x.d << endl;
}
(1) We use the arrow operator since the function has received a pointer to structure variable.
(2) The function f_r() receives a reference and access to the fields is through the dot operator.
(3) We send the address of the object x through the operator (&).
(4) We only write the name of the variable that we want to send, without extra symbols; the compiler already knows that it is a reference.
It might not seem like much right now to change an arrow to a dot, but if you ever decide to use the C++ Standard Library (STL), then you’ll be thankful for the existence of references.
And if you’re still thinking that using references instead of the old pointers isn’t worth it, remember that you can’t send references that point to nothing, which in C (passing null pointers) is a pain in the back. This feature adds a level of security to our programs:
f_p( NULL, 3 ); // Ok in C (source of troubles) f_r( ?, 5 ); // Error at various levels. It won’t compile
Finally I want to mention that many contemporary C++ books avoid or omit the topic of pointers and instead describe and use references (and generally avoid discussing C topics). This is a dead giveaway that we should prefer references to pointers whenever possible; that is, if we are coding one level above the hardware, then let’s use references.
COST: 0
nullptr
Now, either for some kind of sick pleasure or necessity you want or have or need to use pointers, then you should prefer nullptr instead of the macro NULL.
nullptr is a reserved word in C++11 and it represents the address Nil, while NULL is just the value zero (perhaps of an integer type):
int* p = 0; // Ok int* q = nullptr; // Ok int v = NULL; // Ok (warning) int w = nullptr; // Error: nullptr isn’t an integer
Homework: I took this next example from HERE. Without looking at the response, try to determine which function, 1 or 2, is going to be called:
void func(int n); // (1) void func(char *s); // (2) func( NULL ); // which one is called?
(Yes, C++ allows two or more functions to have the same name, as long as their arguments, or number of arguments, are different. This feature is called function overload.)
COST: 0
Finally, I just want to mention that C++11 includes the so-called smart pointers but I do not mention them in this introduction because they are heavily related to dynamic memory, and we try not to use this type of memory in embedded systems. However, if you are going to use it in your project, then you might want to check them out; they are more secure than raw pointers and their cost is almost zero (actually, for the so called unique_ptr() smart pointer the cost is zero).
Constants and alternatives for #define and symbolic constants
Many of our applications use tables or conversions. If the table follows some formula, then we could calculate the value of each element of the table when the program starts. Terrible idea!
If calculating them at runtime is not an option, then we could create a spreadsheet and have it determine the value of each item in the table. It doesn’t sound too bad. The problem is that if the formula depends on a seed value that is also variable, then the spreadsheet solution will not work (think of a table of calculated passwords unique to each microcontroller in a production line).
In embedded systems we like that everything that can be computed at compile time to be computed at compile time. Prior to C++11, and only under certain conditions, this was possible; however, if C++11 determines that a computation can be performed at compile time, then it will do so, as long as we tell it that it is a constant expression.
C++11 introduced the constant expressions (constexpr). A constant expression is an expression that can be evaluated at compile time. Let’s remember that an expression is any construct in the language that computes or returns a result.
In the following example we can see that it is very likely that the expression b=a*8 to be executed when the program is already running, even though it is made up of constants. On the other hand, the expression d=c*8 will be calculated and assigned when the program is being compiled; hence the name of constant expression. In practice it is like having written directly d=40:
int main()
{
int a = 5; // a is neither const nor constexpr
const int b = a * 8; // it might be evaluated when compiling the program
constexpr int c = 5; // c is constant
constexpr int d = c * 8; // it's evaluated when compiling the program
}
On the other hand, it’s very common to declare constants with the #define pre-processor statement:
#define MAX 50
But what is the type of MAX: int, char, unsigned, long, …? Also, the GDB debugger does not handle very well the symbolic constants. #define simply replaces the symbol MAX with the value 50 on each occurrence it finds in our program. How could we add a type to the constant MAX? We can use constexpr to declare symbolic constants:
constexpr uint32_t MAX = 50; // (1)
int main()
{
uint8_t array[ MAX ]={0};
}
(1) We have now stated that MAX is of the type unsigned int (aka: uint32_t).
COST: 0
const vs constexpr
What is the difference between const and constexpr? const declares a variable as read only, but its evaluation will be at runtime (when the program is already running); while constexpr also declares a variable as of read only, but its evaluation is at compile time (when the program is being compiled).
If initializer (from C++17)
As long as we keep the scope of the variables as small as possible, the better. A variable exists from its creation to the closing brace of the block where it was declared. In old C we had to declare all variables at the beginning of functions; later, C99 allowed us to declare variables anywhere in the function, and for a reason: to minimize the risk of using or changing the value of variables by mistake.
C99 already allowed us to declare the control variable within the declaration for the for loop:
for( uint32_t i = 0; i < MAX; ++i )
{
printf( "%d", i ); // Ok: i only exists inside this block ({})
}
i = 5; // Error: i doesn’t exist outside the previous block
In old C, in order to narrow the variable’s scope, we had to do the following:
{
uint32_t i; // i exists from here to the next closing brace
for( i = 0; i < MAX; ++i )
{
printf( "%d", i );
}
i = 5; // Ok: i still exists
} // i stops existing from now on
i = 10; // Error: i doesn't exist outside the previous block
In trivial situations it makes no difference that variables exist for the lifetime of a function; however, when we write secure code we must limit the scope of the variables; that is, from where and for how long they should exist.
However, despite the fact that C99 allows us to declare variables just before using them, sometimes, in both C and C++, we must open a block ({}) that limits the scope of a critical variable that we know shouldn’t exist outside of a certain context (just like the previous example with the variable i). C++17 already allows us to declare the variable within the declaration of the statement if, from what has been called if initializer:
if( init; cond ){}
Instead of coding:
int critical_var = f();
if( critical_var < 10 )
{
// we should use the critical variable just inside this block
}
critical_var = 0; // Ups, we shouldn't, but we can: troubles in the horizon
we can do the following:
if( int critical_var = f(); critical_var < 10 )
{
// critical_var only exist inside this block ({})
}
critical_var = 0; // Error: critical_var doesn’t exist outside the previous block
Another advantage of the if initalizer is that we should not invent names that only obscure the code. Before C++17:
int critical_var = f();
if( critical_var < 10 ){}
unsigned critical_var2 = g(); // Ugly
if( critical_var2 < 10 ){}
With C++17:
if( int critical_var = f(); critical_var < 10 ){}
if( unsigned critical_var = g(); critical_var < 10 ){} // Better!
COST: 0
Extras
auto
C++11 can determine the type of a variable from the context:
float f(){}
auto var = f(); // var is of type float
Non-narrowing initialization
In old C/C++ the following situation is possible:
int a = 9999; char b = a; // It compiles anyway
With C++11 we can somewhat improve this situation by using the initialization without reduction feature:
int a = 9999;
char b = a; // Not even a warning
int c = -1000;
unsigned d{c}; // Wrong, but at least we get a warning
int e{3.14}; // Narrowing error
int f = {3.14}; // Narrowing error (I want to point out the alternative syntax: x={})
Range for
We can iterate collections (arrays) with a new compact form for the for loop: the range-for:
int arr[5] = {2,3,5,7,11};
for( auto& elem : arr )
{
cout << elem << ", ";
}
cout << endl;
Cool, isn’t it?
If our intention is to loop through the collection and do something with each element of the collection, then we can stop using the old for and start using the new range-for loop.
Note: Although the array is made of a basic type (int’s), for efficiency (and muscle memory) it is customary to make the field element be of type reference.
using
Do you use callbacks? I’m pretty sure you do and you need to declare the type of them like:
typedef int( *pf )( int, int );
The reserved word using allows us to declare a function pointer (among other things) in a cleaner way:
using pf = int (*)(int, int);
And in your functions that receive the callback, you continue to use it the same; the only change was in the declaration.
Furthermore, C++11 allows us to move the return type to the end:
using pf = auto (*)(int, int) -> int;
Let’s see a typical example in embedded systems:
typedef void (*pf)(int); // The C way
using pf2 = auto (*)(int) -> void; // Using using
void g( int d ) // The callback
{
cout << d << endl;
}
void DoSomething1( pf user_code ) // Use it as usual
{
user_code( 5 );
}
void DoSomething2( pf2 user_code ) // Use it as usual
{
user_code( 5 );
}
int main()
{
DoSomething1( g );
DoSomething2( g );
}
Before leaving
C++11 and later include a lot of features independent of object-oriented programming that we can start using in our embedded systems.
I couldn’t include all of them in this short introduction; however, the idea behind it is that you start to see C++ as a real (and better) alternative to C.
And as you may have noticed, many of these features come at zero cost, breaking the myth that C++ creates larger executables.
Finally, although using a certain language does not make it more or less secure (that depends on how good the programmer is), C++ makes it easier for us to make our programs more secure, compact, easy to read, and easy to maintain.
Have you already used any of these features? Which is it? Do you want to comment something? Go ahead and let me know in the comments!

Mi perfil completo lo puede encontrar en: https://www.linkedin.com/in/fjrg76-dot-com/
- Arduino and ESP32 whims - diciembre 17, 2025
- Writing Scalable Firmware: Implementing the Command Pattern in C++ - diciembre 4, 2025
- Patrón de diseño de software Command para sistemas embebidos para los no iniciados - noviembre 30, 2025
2 COMENTARIOS