Cómo crear componenes de software intercambiables para sistemas embebidos. Desacopla la lógica del hardware (Parte I)
(Read this article in english here.)
Introducción
Si no usas interfaces, entonces no has entendido la programación orientada a objetos.
(Leído en algún lado recientemente.)
Hace unos días les compartí una clase (Blink) para controlar periféricos binarios (LEDs, relevadores, búzzers, etc). Esta clase, además de ser muy útil, me gustó mucho. Sin embargo, tiene algo que no me deja en paz: debemos inyectarle una función que interactúe con el hardware.
Aunque a esta clase la pensé y la diseñé de manera genérica (abstracción), utilicé la plataforma Arduino para el desarrollo (implementación). Las terminales de entrada/salida en Arduino son un simple número entero (0, 1, 2, …), pero en todas las otras plataformas una terminal está determinada por un puerto y un número entero, e inclusive más parámetros. La siguiente línea pertenece a un programa en el procesador LPC1114 de NXP:
Chip_GPIO_SetPinState (LPC_GPIO, port, pin, new_state);
¿La firma de la función inyectada debería incluir únicamente un parámetro para la terminal que será controlada (Arduino), o debe incluir dos parámetros, uno para el puerto y otro para la terminal (como en el resto de plataformas)? ¿O debemos tener dos o más versiones de la clase Blink?
Sigue leyendo para mostrarte cómo podemos solucionar este problema utilizando componentes de software intercambiables.
Veamos el mismo problema pero desde una perspectiva diferente.
Imagina el siguiente escenario: tienes que escribir un programa para un procesador que estará montado en un circuito impreso. La tarea es simple: la tarjeta incluirá un LED conectado directamente al procesador y tú deberás controlarlo.
Toma en cuenta que el control del LED no es exactamente trivial (échale un ojo a mi clase Blink) por lo cual vas a necesitar una clase controladora; esta clase le vamos a llamar Blink (mucho más simple, para efectos de esta explicación, que la Blink original).
Pero hay más. Tu cliente aún no se decide por el procesador y, para empeorar las cosas, ya te hizo saber que más adelante habrá una segunda versión del hardware que utilizará un expansor de terminales (como el PCF8574) con el LED conectado a uno de ellos, y quizás se usará una variante del procesador original.
Como habrás notado, algunos verbos están en futuro y ello implica que:
- Hoy NO tienes la primera versión de la tarjeta.
- Hoy NO tienes la segunda versión de la tarjeta.
- Hoy NO sabes qué otra cosa se le podría ocurrir a tu cliente (por ejemplo, controlar un LED de manera remota, a través de una UART, o cambiar a un procesador diferente).
- Hoy te tienes que poner a trabajar inmediatamente porque tu cliente ya comenzó a pagarte; esto es, no deberías esperar a recibir el hardware para comenzar el desarrollo.
¿Qué harías?
- Utilizar un hardware alternativo para comenzar el desarrollo (Arduino UNO, ST Discovery, Raspberry Pi Pico, etc). Suena bien. ¿Con cuál de los 3 escenarios futuros vas a empezar: el LED on-board, el LED en el expansor, o el LED que usa la UART? Si programas implementaciones ¡vas a terminar con 3 versiones de la clase controladora Blink!
Aquí tenemos tres problemas,
- Repetición de código. Habrás escrito 3 versiones prácticamente idénticas del código fuente. ¿Qué pasaría si descubres un error en la lógica? Tendrías que editar el código en todas tus versiones.
- Subir el programa al procesador en cada una de las plataformas de hardware mencionadas toma algo de tiempo (¿has subido código a la ESP32/ESP8266?), por lo cual pequeños cambios en el programa harán que el tiempo de desarrollo se alargue.
- Y algo muy importante, quizás en estas plataformas no tengas acceso a un depurador de código (como GDB), por lo cual el tiempo de desarrollo se alargará todavía más.
- Escribir y probar la clase controladora en tu computadora de escritorio y simular el LED en la misma PC. ¡Ésta me gusta!.
Piensa que el LED on-board, el LED en el expansor y el LED simulado en la PC son componentes de software intercambiables. Y piensa en la clase controladora Blink como una clase que acepta componentes.
Tu flujo de trabajo podría ser así:
- Diseñas la interfaz para tus futuros componentes.
- Escribes en la PC el componente LedPC mientras llega la primera versión del hardware.
- Escribes, pruebas y depuras en la PC la clase controladora Blink utilizando el componente LedPC anterior.
- Escribes el componente LedOnBoard cuando recibas la primera versión del hardware y la pruebas en el nuevo hardware con el compilador correspondiente.
- Escribes el componente LedXpander cuando recibas la segunda versión del hardware y la pruebas en el nuevo hardware con el compilador correspondiente.
Escribiste 3 componentes intercambiables y una sola versión de la clase controladora Blink. Y por favor nota algo muy importante y sutil: la clase Blink es independiente del hardware.
¡Parece ciencia ficción!
Interfaces
¿Cómo puedes lograr todo esto? Con las interfaces. Una interfaz es un contrato que establece el comportamiento que deben cumplir las clases que la implementen, y si tu clase controladora y los diferentes componentes la honran, entonces habrás programado interfaces (a diferencia de programar implementaciones). En corto, programar interfaces significa enfocarse en el qué, no en el cómo.
La forma más fácil de escribir interfaces en C++ es con clases base abstractas, métodos virtuales puros y polimorfismo (más adelante explico otras dos formas):
struct My_Interface
{
virtual return_type method1( /*args_list*/ ) = 0;
virtual return_type method2( /*args_list*/ ) = 0;
// more virtual pure methods
};
Nota que:
- Únicamente está listado el comportamiento (esto es, los métodos), es decir, el qué.
- Todos los métodos son virtuales puros. Recuerda que así se forman las clases base abstractas en C++.
- No tiene constructor.
- No existe un estado que guardar (esto es, no tiene atributos).
Lo anterior fue descrito por el gurú de la programación Robert C. Martin:
“1. High-level modules should not depend on low-level modules. Both should depend on abstractions.
2. Abstractions should not depend on details. Details should depend on abstractions.”
(“1. Módulos de alto nivel no deberían depender en niveles de bajo nivel. Ambos deberían depender en abstracciones.
2. Las abstracciones no deberían depender en los detalles. Los detalles deberían depender de las abstracciones.”)
Esto es, en una arquitectura basada en capas, entre dos de éstas debe existir una capa de abstracción. Esta capa intermedia permitirá que la capa superior o inferior cambien con mínimas (o cero) afectaciones al sistema, como lo muestra el siguiente diagrama:
En este proyecto la capa de abstracción es la interfaz, los componentes son la capa inferior (implementación), y la clase controladora (cliente) es la capa superior.
El punto 2 establece que una abstracción debe contener únicamente la funcionalidad (métodos, funciones) y no detalles (estado, atributos). Quien sea que quiera usar a la abstracción deberá proveer el código de los métodos de la interfaz (esto es la implementación y los detalles).
Si te gusta la diagramación UML, este diagrama es más formal y representa a todos los elementos involucrados en el sistema. En la sección Desarrollo del ejemplo estudiaremos elemento por elemento.
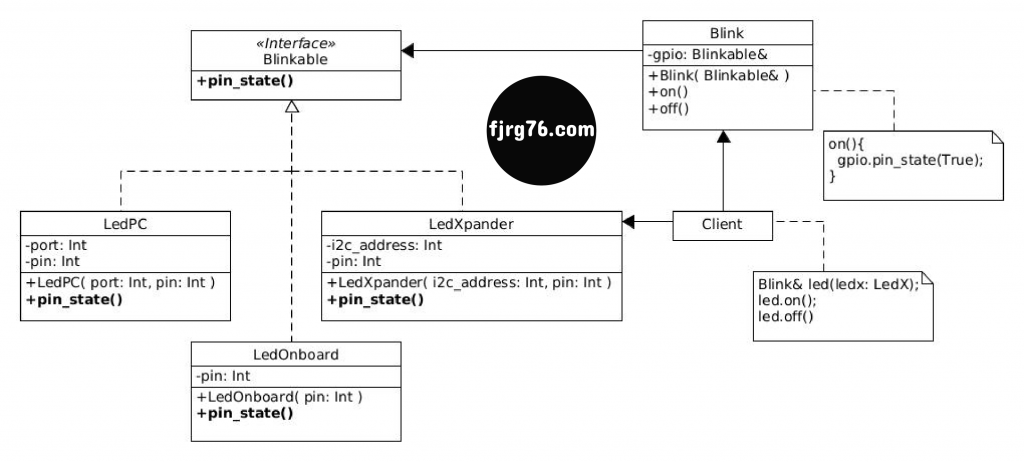
Implementación de la interfaz
Cuando decimos que una clase implementará a una interfaz nos estamos refiriendo a una clase que va a heredar de la interfaz y va proveer el código correspondiente a los métodos virtuales puros de su clase base:
class My_implementation : public My_Interface
{
private:
/* some state and attributes */
public:
My_implementation( /*args_list*/ );
/* optional in embedded systems:*/ virtual ~My_implementation();
return_type method1( /*args_list*/ ) override
{
// code that implements method1() behavior
}
return_type method2( /*args_list*/ ) override
{
// code that implements method2() behavior
}
/* more methods if need it */
}
En lenguajes que no soportan componentes (C, C++, Java) la programación orientada a componentes se realiza a través de las interfaces, como recién lo describí, a nivel binario; esto es, dentro del mismo código ejecutable (a diferencia de las bibliotecas dinámicas, por ejemplo).
Por supuesto que el tema de componentes es mucho más amplio que eso, pero para los fines que me he propuesto, y que han superado mis expectativas y por mucho, me es suficiente con escribir diferentes implementaciones de la interfaz (los componentes) y la clase controladora (la que recibe los componentes).
Desarrollo de un ejemplo con polimorfismo dinámico
Vamos a resolver los dos problemas presentados en la introducción utilizando interfaces, componentes y clases base abstractas (son el mismo problema, pero con puntos de vista diferentes).
1 Diseñando la interfaz
Nuestra interfaz consta de un sólo método que activará o desactivará (prender/apagar, poner a 1/0, etc) un terminal del procesador. Le vamos a llamar IBlinkable. La “I” es por “Interfaz” y es costumbre que esa letra preceda al nombre de la clase:
struct IBlinkable
{
virtual void pin_state( bool new_state ) = 0;
};
2 Escribiendo un componente para la PC
A partir de la interfaz anterior vamos a escribir nuestro primer componente, el cual simulará en la PC el comportamiento de un LED:
class LedPC : public IBlinkable
{
private:
uint32_t port; // hardware port (placeholder)
uint8_t pin; // hardware pin (placeholder)
public:
LedPC( uint32_t port, uint8_t pin ) : port{port}, pin{pin}
{
std::cout << "LedPC::LedPC()\n";
}
// mocked behavior:
void pin_state( bool new_state ) override
{
std::cout << (new_state == false ? "LedPC::OFF" : "LedPC::ON") << std::endl;
}
};
Dado que estamos simulando el comportamiento de un Led en la PC y no podemos ver si está prendido o apagado, en su lugar escribimos un mensaje en la pantalla que nos permita conocer si el resultado es lo que esperamos.
Los atributos port y pin no se usan, pero te muestran que las implementaciones pueden tener cuantos atributos (variables de estado) sean necesarios.
3 Escribiendo la clase controladora Blink
Ya armados con nuestro primer componente es tiempo de escribir a la clase que los recibirá, la cual he estado llamando clase controladora y a quien le he dado el nombre Blink:
class Blink
{
private:
IBlinkable& gpio; // component receiver
public:
Blink( IBlinkable& new_gpio ) : gpio{new_gpio}
{
// if needed
}
void on()
{
gpio.pin_state( true );
}
void off()
{
gpio.pin_state( false );
}
};
El atributo gpio es una referencia a una implementación particular de la interfaz Blinkable; es decir, aquí guardaremos la referencia al componente que le conectemos. La inicialización del resto de atributos de esta clase (si los hubiera) se hace en el constructor.
Los métodos .on() y .off() son quienes interactúan con el componente a través de su referencia llamando a los métodos que implementan a los métodos virtuales puros de la interfaz (en nuestro caso solamente uno).
Una vez que tenemos a la clase controladora, y al menos un componente, es tiempo de comenzar a probar la magia:
int main()
{
LedPC led_pc( 0x1234, 10 );
Blink led( led_pc );
led.on();
led.off();
}
Primero creamos una instancia del componente LedPC y después la vinculamos con la instancia led de la clase controladora. led es quien hace las veces de cliente del componente led_pc y es a quien nosotros estaremos usando a lo largo del proyecto en el que estemos trabajando.
Una ejecución del código que hemos visto hasta este momento es:

NOTA: Dado que escribí todo el código en un sólo archivo (para fines explicativos) tuve que usar unas constantes para establecer contra cuál componente voy a compilar cada vez.
¡Por favor no dejes de notar que estamos ejecutando un LED en la computadora de escritorio!
4 Escribiendo el componente del Led on-board
Cuando tengas en tus manos la primera versión del hardware lo único que tendrás que hacer es escribir el componente LedOnBoard, conectárselo a una instancia de la clase controladora Blink (la cual es la misma del paso 3, y que en teoría ya funciona correctamente), y compilar para el procesador utilizado.
Vamos a suponer que el hardware está basado en el procesador ATMEGA328 y que funciona como si fuera la plataforma Arduino (en ésta las terminales están identificadas con un número entero únicamente):
// Class IBlinkable as before
class LedOnBoard : public IBlinkable
{
private:
uint8_t pin; // maybe it is an Arduino implementation
public:
LedOnBoard( uint8_t pin ) : pin{pin}
{
pinMode( this->pin, OUTPUT ); // real hardware
}
void pin_state( bool new_state ) override
{
digitalWrite( this->pin, new_state ); // real hardware
}
};
// Class Blink as before
int main()
{
LedOnBoard led_on_board( 13 ); // (1)
Blink led( led_on_board ); // (2)
led.on();
led.off();
}
- En esta implementación particular de la interfaz hemos utilizado al constructor para configurar a la terminal como salida.
- Después conectamos el componente
led_on_boarda la clase controladora. - Y finalmente hacemos las llamadas a los métodos
led.on()yled.off().
Ambos, efectivamente, mandan llamar al método LedOnboard::pin_state() (gracias al polimorfismo), y éste a su vez manda llamar a la función de Arduino digitalWrite() para cambiar el estado de una terminal.
5 Escribiendo el componente para la segunda versión del hardware
El tiempo pasó y la amenaza de tu cliente se cumplió: la segunda versión del hardware conecta el LED a una terminal de un expansor de puertos I2C (como el PCF8574).
Afortunadamente en este punto tú ya eres experto en componentes y lo único que vas a hacer es escribir una implementación de la interfaz para esta nueva versión del hardware:
// Class IBlinkable as before
class LedXpander : public IBlinkable
{
private:
uint8_t i2c_address; // xpander (PCF8574) I2C address
uint8_t pin; // 0-7
public:
LedXpander( uint8_t i2c_address, uint8_t pin ) : i2c_address{i2c_address}, pin{pin}
{
//i2c_config();
}
void pin_state( bool new_state ) override
{
uint8_t port_val = i2c_read( this->address );
port_val = new_state==false ?
port_val & ~bit_mask[this->pin] :
port_val | bit_mask[this->pin];
i2c_write( this->address, port_val );
}
};
// Class Blink as before
int main()
{
LedXpander led_xpander( 0x20, // 7bit i2c address
3 ); // pin on the xpander chip
Blink led( led_xpander );
led.on();
led.off();
}
Para este nuevo componente no hay mucho que decir que no se haya dicho ya. El constructor del mismo obtiene la dirección I2C y el número de pin, e inicializa los atributos correspondientes, y quizás inicializa al módulo I2C del microcontrolador.
Después, el método que implementa a la interfaz, pin_state(), llama a las funciones del bus I2C para escribir en el dispositivo PCF8574 (o equivalente).
Por favor nota que ya no tuviste que modificar a la clase controladora Blink, sólo tuviste que crear el componente y conectárselo. ¿Así o más fácil?
La siguiente imagen muestra a los 3 componentes (todos simulados para efectos de la explicación) siendo conectados a la clase controladora Blink, ¡y funcionando correctamente!
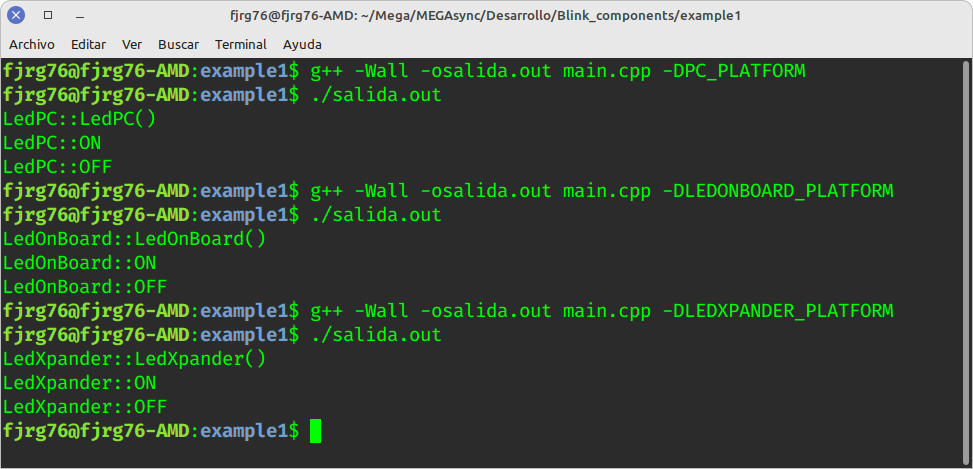
Más componentes
A partir de este punto puedes:
- Escribir cuantos componentes necesites (quizás un LED que se controle por la UART o por Wi-Fi).
- Utilizar los componentes que has escrito con clientes diferentes en proyectos diferentes (clases diferentes a
Blinkque requieran controlar un LED).
¡Escribes una vez y usas muchas veces!
Nombres de los componentes
He utilizado nombres diferentes para los diferentes componentes en el desarrollo del ejemplo; sin embargo esto no tiene porqué ser así. Si mantienes una correcta organización de los archivos de tu proyecto, entonces podrías utilizar el mismo nombre para los diferentes componentes. Y de hacerlo así ¡la magia sería más sorprendente!
Cambios en la función controladora
Una ventaja de usar la capa de abstracción (la interfaz en este proyecto) es que si algún día la lógica de la función controladora tuviese que cambiar (lo cual ciertamente pasará) vas a poder hacer los cambios necesarios de forma sencilla y rápida, debido a que por un lado solamente deberás modificar el código de la clase controladora (sin tocar el código de los componentes que habías escrito). Y por otro lado, el desarrollo de la nueva lógica lo podrás hacer de vuelta en la computadora de escritorio utilizando al componente de LED simulado y quizás al depurador GDB, ¡sin liarte con el hardware!
Alternativas al polimorfismo dinámico y los métodos virtuales
“Oye, pero las interfaces usan polimorfismo dinámico y métodos virtuales y desde nuestra infancia se nos ha dicho que debemos evitarlas en los sistemas embebidos”. Es cierto, pero no del todo.
Los métodos virtuales implican una búsqueda en una tabla, vtable, lo cual incurre en costos de tiempo y espacio. Sin embargo, seamos honestos: toda la vida hemos utilizado apuntadores a funciones casi sin pensarlo, ¿por qué con el polimorfismo dinámico debe ser diferente?
En nuestros sistemas embebidos no va a suceder que cambies el componente LedOnboard por el componente LedXpander cuando el programa se está ejecutando, ¡así no funciona el mundo para nosotros!. Esto significa que la asignación del componente LedOnboard (y a efectos prácticos, cualquier componente que implemente la interfaz) se realizará una sola vez durante la vida del programa:
Blink led( led_on_board ); // ¡una sola vez!
Por otro lado, hay buenas noticias (más o menos) si insistes en no querer utilizar al polimorfismo dinámico. Existen (al menos) otras dos formas de escribir las interfaces:
- Con polimorfismo estático.
- Con archivos de encabezado.
Así como la programación orientada a objetos está en la cabeza del programador y no en el lenguaje de programación (¿sabías que puedes programar con objetos en C y Pascal?), las interfaces también están en la cabeza del programador.
Una interfaz en C++ puede realizarse de varias formas:
- Una clase base abstracta (como ya lo vimos), haciendo que todos los métodos sean virtuales puros. Utiliza polimorfismo dinámico: el vínculo entre los métodos y sus implementaciones se realiza en tiempo de ejecución. Esta es la forma que utilicé en el ejemplo anterior.
- Una clase base templatizada*. Utiliza polimorfismo estático a través del patrón esotérico CRTP de C++: el vínculo entre los métodos y sus implementaciones se realiza en tiempo de compilación. El mismo ejemplo que hemos visto, pero usando esta forma, es tema de una segunda parte de este artículo.
- Un archivo de encabezado (.h ó .hpp) con el conjunto de declaraciones de las funciones de la interfaz. El mismo ejemplo que hemos visto, pero usando esta forma, te lo estaré pasando como un anexo a esta serie.
*El nombre en inglés es templetized base class, y utiliza plantillas (templates); sin embargo, no encuentro una traducción decente (la más cercana es “clase base plantillizada” ¿?). La expresión “clase base basada en plantillas” no refleja la intención del patrón CRTP, pero bajo ciertos escenarios podría usarse sin mayor inconveniente.
Veamos ahora ventajas y desventajas de cada una de las diferentes formas de escribir las interfaces:
- Fácil de implementar, pero tiene un pequeño costo en espacio y usa tiempo de ejecución. No es demasiado, pero los puristas de los sistemas embebidos podrían no estar de acuerdo en usarlo.
- Extremadamente difícil de comprender, fácil de implementar, y no incurre en costos ni de espacio ni de tiempo.
- Fácil de implementar, pero pierde las bondades y ventajas de los mecanismos que provee C++ para la POO. Esta forma es ideal si no cuentas con un compilador de C++ o las dos formas anteriores no llenan tus expectativas.
Relacionado con las 3 formas anteriores de escribir interfaces, los autores Jhon y Wayne T. Taylor en su libro “Patterns in the Machine” (Apress, 2021) escribieron:
“An abstract interface does not have to be a pure virtual class in C++. An abstract interface is any interface that defines a behavior that has a deferred binding (i.e., not a source time binding) for its implementation.”
(“Una interfaz abstracta no tiene que ser una clase virtual pura en C++. Una interfaz abstracta es cualquier interfaz que defina un comportamiento que tenga un enlace diferido (…) de su implementación.”)
(Source time binding se refiere a la compilación condicional, la cual no cuenta como interfaz.)
Esto es a lo que me refería cuando dije “las interfaces están en la cabeza de los programadores”. El punto es que exista un contrato, en cualquier forma, y que las diferentes partes que forman al sistema lo honren.
A modo de introducción te platico de que van estas otras dos formas de implementar interfaces (en lo que escribo la segunda y tercera parte de esta serie).
Interfaces con polimorfismo estático y el patrón CRTP
Mientras que el polimorfismo dinámico realiza el vínculo entre el objeto y el mensaje cuando la aplicación ya está ejecutándose; el polimorfismo estático vincula el objeto y el mensaje en tiempo de compilación, y no incurre en costos de tiempo y espacio. ¿A cambio de qué?
El polimorfismo estático se basa en un concepto fascinante, oscuro, complejo, esotérico, y fuera de este mundo de C++ que se conoce como el patrón CRTP, Curiously Recursive Template Pattern, y su implementación es peor que su nombre (en realidad la implementación es muy simple una vez que entendiste el concepto, pero ahí es donde reside el problema, la comprensión del concepto). Una vez que has asimilado el concepto el cielo se te abre… pero en lo que eso sucede tu cerebro te va a explotar varias veces.
Espero que los ejemplos que te voy a presentar en la segunda parte de esta serie te aclaren las ideas sobre este patrón.
En lo que la segunda parte llega, aquí te dejo un par de artículos que escribí en mi blog alternativo y en los cuales traté este tema (desafortunadamente están en inglés):
Interfaces con archivos de encabezado
Quizás ésta sea la forma más fácil de implementar las interfaces, siempre y cuando el o los programadores se ajusten a los lineamientos establecidos y no se salgan de ellos. La declaración de una función es una interfaz primitiva, pero interfaz al final de cuentas. Si no cumples con el contrato, entonces el compilador rechazará tu código.
La implementación de la función provee el código (o los códigos, uno por componente) que satisface a la declaración de la función de la interfaz. Su costo en tiempo y espacio es nulo.
Organización de los archivos del proyecto
Hasta el momento he omitido un concepto importante en la descripción que he hecho: la organización de los archivos del proyecto.
Para sacar el máximo provecho de esta forma de programar componentes es imperativo que mantengas una estructura de los archivos del proyecto que permita la convivencia de los diferentes componentes al mismo tiempo (a nivel de disco duro) y un fácil y correcto intercambio de ellos (para que puedas desarrollar y probar en la PC y después, de manera fácil y rápida, lo integres al hardware cuando esté listo).
En el siguiente ejemplo, al final, te mostraré una estructura simple de archivos para que te des una idea.
Ejemplo completo
Aquí puedes hacerte de una copia del ejemplo completo que incluye a la clase controladora y los tres componentes desarrollados.
Notarás que todo lo hice en un mismo archivo para no oscurecer el punto principal de este artículo y todos corren en la PC. Sin embargo, para un proyecto real me permito insistir en una correcta organización del código fuente.
El repositorio también incluye el código de la versión con polimorfismo estático, en caso de que quieras revisarlo en lo que escribo el artículo.
Arduino
En el caso de que quieras llevar estas ideas a la práctica con Arduino deberás abandonar su (horrible) IDE y buscar alternativas. En lo personal yo utilizo Arduino con archivos makefile, Arduino-Makefile.
El problema de la IDE de Arduino es que es muy tonta para manejar proyectos multiarchivo, y aunque un par de soluciones podrían ser copiar y pegar archivos o crear enlaces simbólicos, éstas no escalan bien. Cuando empiezas a programar con componentes estás entrando a un nivel que la IDE no puede manejar.
Palabras finales
Desacopla la lógica del hardware programando interfaces.
Como pudiste observar, programar con interfaces son un concepto muy importante y puede ser utilizado más allá de componentes.
De las muchas ventajas que tiene la programación orientada a componentes la que más me agrada es tener la posibilidad de escribir la lógica (casi siempre compleja) en la computadora de escritorio porque además de la velocidad de desarrollo puedo utilizar TDD (Test Driven Development, ó en español, Desarrollo dirigido por pruebas).
Y si las cosas no van bien, entonces puedo utilizar al depurador GDB para encontrar rápidamente los problemas. ¿Podemos hacer lo mismo sobre el hardware, como por ejemplo, un procesador ARM con un depurador externo (j-link)? Sí, pero la velocidad de desarrollo en la PC es mucho mayor.
Espero que esta primera parte de esta serie haya sido de tu agrado. Si no te has suscrito a mi blog hazlo en este momento para que las dos partes restantes las recibas inmediatamente.
Enlaces patrocinados. Los tengo, los leí y los recomiendo:

Este libro trata ampliamente sobre la separación de la lógica de nuestras aplicaciones del hardware que la implementa.

Este libro trata sobre diferentes formas de aplicar el desarrollo dirigido por pruebas en hardware para nuestros sistemas embebidos.
Más productos interesantes (enlaces de afiliado):
- Arduino UNO original: https://amzn.to/3MH8zvx
- Arduino Nano Every, 3 pack: https://amzn.to/3KwNi5X
- STM32FDISCOVERY: https://amzn.to/3vTtrsu
- Raspberry Pi Pico, kit básico: https://amzn.to/3xZwHFk
Circuitos impresos

Además de escribir artículos también diseño circuitos impresos. ¡Búscame en Fiverr!.
¿Ya conoces mi curso gratuito de Arduino en tiempo real, utilizando el Arduino UNO o el Arduino Due y FreeRTOS?
¿Te gustaría ser de los primeros en recibir las actualizaciones a mi blog? ¡Suscríbete, es gratis!

Mi perfil completo lo puede encontrar en: https://www.linkedin.com/in/fjrg76-dot-com/
- Arduino and ESP32 whims - diciembre 17, 2025
- Writing Scalable Firmware: Implementing the Command Pattern in C++ - diciembre 4, 2025
- Patrón de diseño de software Command para sistemas embebidos para los no iniciados - noviembre 30, 2025
3 COMENTARIOS